C
strncpy, strncat
char * strncpy ( char * destination, const char * source, size_t num );
char * strncat ( char * destination, const char * source, size_t num );
destination ist nicht null-terminiert, wenn strlen(source) >= num
Besser ist Folgendes:
// Ineffizient wenn src deutlich kürzer, weil Rest von dest mit 0 gefüllt wird
char dest[64] = "";
strncpy(dest, src, sizeof(dest) - 1);
dest[sizeof(dest)-1] = 0
// Besser (-1 als Platz fur \0)
dest[0] = 0;
strncat(dest, src, sizeof(dest) - 1);
// Anhängen an Vorhandenes
strncat(dest, src, sizeof(dest) - strlen(dest) - 1);
strncpy füllt Buffer komplett mit 0 auf, wenn strlen(source) < num, daher bei strings mit deutlich unterschiedlicher Länger als Alternative strncat oder memmove in Betracht ziehen!
Operator Precedence
https://en.cppreference.com/w/c/language/operator_precedence
a & b == c wird als a & (b == c) evaluiert (gleiches gilt für die anderen bitwise Operatoren ^ | und Vergleiche < > <= >=).
Evaluations Reihenfolge: (quasi alle Operatoren) -> & AND -> ^ XOR -> | OR -> Logical -> ternary -> assignment -> comma operator
<< und >> werden nach +-*/ evaluiert, aber vor den meisten anderen Operatoren
Dynamischer Array ohne Templates
https://github.com/tree-sitter/tree-sitter/blob/master/lib/src/array.h
Nutzt macro zur Definition eines eigenen structs pro Type.
malloc + sizeof
struct someStruct *var = malloc(sizeof(struct someStruct));
// better (code does not need to change if type changes):
struct someStruct *var = malloc(sizeof(*var));
// usually even better (fills with 0)
struct someStruct *var = calloc(1, sizeof(*var));
// usually even better (shorter, on stack, 0 init when static or one member is set in struct literal):
// NOTE: inits to default values in C++ (0 if no defaults given)
struct someStruct var = {.member = 1, ...};
struct someStruct var = {0};
https://felipec.wordpress.com/2024/03/03/c-skill-issue-how-the-white-house-is-wrong/
malloc / calloc / realloc pitfalls
- malloc and realloc take NUMBER OF BYTES as argument, calloc takes NUMBER OF ELEMENTS and ELEMENT SIZE
- do not call realloc with size 0 instead of free. Behavior is implementation defined and not necessarily equivalent (source) - in C23 it is even undefined behavior!
- realloc is not guaranteed to re-use the existing block of memory (even if new size is smaller), so do not rely on it (e.g. you need to update pointers to this variable)
- calloc 0-initializes the memory, malloc and realloc do NOT
- it IS OK to call realloc with a nullptr argument, it behaves the same as malloc then
- do NOT call free twice on the same pointr. It IS OK to call free on a nullptr.
offsetof, container_of macro
offsetof gets the byte offset for a member in a struct:
// Check if order of memers in two structs are equal
// So one can be casted into the other
static_assert(offsetof(Vector2, x) == offsetof(Rectangle, x) && offsetof(Vector2, y) == offsetof(Rectangle, y));
container_of() is part of the Linux kernel and basically does the reverse, pass in a pointer to a member and get a pointer for the surrounding type: https://radek.io/2012/11/10/magical-container_of-macro/
Macro stringification
#define MAKESTRING(n) STRING(n)
#define STRING(n) #n
// prints __LINE__ (not expanded)
std::cout << STRING(__LINE__) << std::endl;
// prints 42 (line number)
std::cout << MAKESTRING(__LINE__) << std::endl;
This is the stringize operation, it will produce a string literal from macro parameter (n). Two lines are required to allow extra expansion of macro parameter. (https://stackoverflow.com/a/48464280)
OpenMP - Simple Parallelisierung
OpenMP and pwrite() (nullprogram.com)
/* schedule(dynamic, 1): treat the loop like a work queue */
#pragma omp parallel for schedule(dynamic, 1)
for (int i = 0; i < num_frames; i++) {
struct frame *frame = malloc(sizeof(*frame));
float theta = compute_theta(i);
compute_frame(frame, theta, beta);
// only one thread at a time can be in the critical section
#pragma omp critical
{
write(STDOUT_FILENO, frame, sizeof(*frame));
}
free(frame);
}
#pragma wird ignoriert, wenn OpenMP nicht unterstützt wird -> Code läuft normal ab, wird nur nicht parallelisiert.
Wird auch von Windows unterstützt (bis OpenMP 2.0)
switch
switch wird in Assembler als Jump-Table umgesetzt. Input wird in Speicheradresse umgerechnet, an der sich der Code für die korrekte Anweisung aus dem switch befindet.
Complexity: O(1) + C
if-tree Complexity: O(n) + K | K < C
-> schneller als if-tree wenn man viele Bedingungen hat
https://www.youtube.com/watch?v=fjUG_y5ZaL4
Compiler, Linker
Preprocessor only:
> gcc -E main.c -o main.i
Compiler:
> gcc -S main.i -o main.s
Assembler:
> as main.s -o main.o
Preprocessor + Compiler + Assembler:
> gcc -c main.c -o main.o
Linker:
> ld obj1.o /usr/lib/obj2.o -lc main.o -dynamic-linker dynamiclib.so -o main.exe
Full pipeline:
> gcc -o out.exe ./main.c -llibraryname -LLibrary/directory
Compiler generiert Object-Datei (.o, .obj). Diese enthält Assembler + Informationen zu Abhängigkeiten und Aufbau für Linker.
Linker verbindet mehrere Objekt-Dateien zu einer Executable.
Dump Assembler:
> gcc -S file.c
> gcc -S -o asm_output.s file.c
Dump from Object-file:
(-S intermixes source code)
(-rwC show symbol relocations, disable line-wrapping, demangle)
> objdump -S -d -rwC -Mintel file.o > file.dump
Dump Assembler optimized:
https://stackoverflow.com/a/38552509
> g++ -fno-asynchronous-unwind-tables -fno-exceptions -fno-rtti -fverbose-asm -Wall -Wextra foo.cpp -O3 -masm=intel -S -o- | less
Show dependencies:
ldd main.exe
p == NULL vs NULL == p
void *p = malloc(8);
if (p = NULL) {} // no error, p is assigned NULL
if (NULL = p) {} // error, we wanted to write NULL == p
main()
main() wird vom Compiler anders optimiert, da die Funktion nur einmal aufgerufen wird (Aussage irgendwo bei Stackoverflow gelesen)
Bit Hacks
https://graphics.stanford.edu/~seander/bithacks.html#CountBitsSetParallel
Count set bits in an int32 and more...
Bitmask with more than 64 entries
internal b32
EntityHasProperty(Entity *entity, EntityProperty property)
{
return !!(entity->properties[property / 64] & (1ull << (property % 64)));
}
internal Entity *
SetEntityProperty(Entity *entity, EntityProperty property)
{
entity->properties[property / 64] |= 1ull << (property % 64);
return entity;
}
enum EntityProperty {
ENT_PROP_NONE=0,
ENT_PROP_TOGGLE,
//...
EntityProperty_MAX
}
#define EntityProperty_MAX 123
struct Entity {
u64 properties[(EntityProperty_MAX+63)/64];
// ...
}
Simple solution of using an "automatically" scaling array (at compile time) and accessor functions, which target the right entry for a given value.
Stack space
Stack space is limited and you can run out, especially if you place a large array on it.
Default limits
- MSVC: 1MB
- Linux: 8MB (defined by OS)
To increase the limit - MSVC:
/Fcompiler option Documentation - GCC (Windows):
-Wl,--stack,<bytes>option Source - Linux:
ulimit -s(globally) or locally
If you run out of stack due to allocations, the program might crash directly after startup (usually without an error message). The error will be in thechkstk.asmmodule. c++ - App crash after modifying a structure - Stack Overflow
Opaque struct
// foo.h
typedef struct foo foo;
foo *init();
void doStuff(foo *f);
void freeFoo(foo *f);
// foo.c
struct foo {
int x;
int y;
};
Hides internal details, datamembers and functions of a struct from the user (i.e. only the struct name is known to the public API). Essentially this means: do not access the internals of this struct manually, only pass it to the accompanying API functions. Is the equivalent of making things protected/private in C++.
Advantage: Implementation details of struct can change and user-code is unaffected.
Allows multiple implementations of the same concept/interface (e.g. for platform specific code)
Bitshift
// >> shifts all bits right and fills with 0 (+int and uint) or 1 (-int, preserves sign bit, technically compiler dependant)
// -1 is all bits=1 in two's complement
// << always fills with 0 and preserves sign bit on int
int test = 1;
printf("%d | %d\n", test << 2, test >> 2);
// prints 4 | 0
test = -1;
printf("%d %d\n", test << 2, test >> 2);
// prints -4 | -1
More info: https://en.wikipedia.org/wiki/Bitwise_operations_in_C#Right_shift_>>
Rounding
val | cast | floorf | roundf | ceilf
-1.9 | -1 | -2.0 | -2.0 | -1.0
-1.5 | -1 | -2.0 | -2.0 | -1.0
-1.2 | -1 | -2.0 | -1.0 | -1.0
-0.9 | 0 | -1.0 | -1.0 | -0.0
-0.5 | 0 | -1.0 | -1.0 | -0.0
-0.1 | 0 | -1.0 | -0.0 | -0.0
0.1 | 0 | 0.0 | 0.0 | 1.0
0.5 | 0 | 0.0 | 1.0 | 1.0
0.9 | 0 | 0.0 | 1.0 | 1.0
1.2 | 1 | 1.0 | 1.0 | 2.0
1.5 | 1 | 1.0 | 2.0 | 2.0
1.9 | 1 | 1.0 | 2.0 | 2.0
- (int)-cast not recommended for values that can be both positive and negative, since the range (-1,1) gets mapped to 0, basically introducing an off-by-one error whenever we cross 0 (e.g. when dealing with 2D/3D coordinates)
- floorf and ceilf are more consistent and map the same amount of values to a single int across the whole range of float/double
- roundf has the problem that both +0.5 and -0.5 get rounded away from zero and one has to deal with the fact, that the switch from one int to the next happens in the middle between two values
#include <stdout.h>
int main()
{
float values[] = {-1.9, -1.5, -1.2, -0.9, -0.5, -0.1, 0.1, 0.5, 0.9, 1.2, 1.5, 1.9};
printf(" val | cast | floorf | roundf | ceilf\n");
for (int idx = 0; idx < sizeof(values) / sizeof(values[0]); ++idx)
{
float v = values[idx];
printf("% 4.1f | %4d | % 6.1f | % 6.1f | % 4.1f\n", v, (int)v, floorf(v), roundf(v), ceilf(v));
}
}
int sizes
#include <stdint.h>
int64_t test = -(1ULL << 32) - 2;
int32_t test2 = test;
printf("%lld %d\n", test, test2);
// prints: -4294967298 -2
- Casting a bigger int type to a smaller one will preserve the lower N-1 bits and the sign (or lower N bits for unsigned types)
Implicit conversions
Implicit conversions - cppreference.com
Breaking it down to practical rules (ignoring niche use-cases like complex and imaginary types).
Two different types as argument in an arithmetic operation are converted as follows:
- an integer is converted to match a floating type
- the smaller type is converted to match the larger type
- signed integers are converted to unsigned, unless the signed type can represent all possible values of the unsigned type (i.e. the signed type is bigger)
Examples:
// rule 1
1.f + 20000001 // 20000001 is converted to float 20000000.f
// result after addition is float 20000000.f
// (since 20000001.f is not representable)
// rule 2
1.f + 2.0 // 1.f is converted to double 1.0
// result after addition is double 3.0
(char)'a' + 1L // (char)'a' is converted to long 97
// result after addition is signed long 98
5UL - 2ULL // 2UL is converted to unsigned long long 2
// result after addition is unsigned long long 3
// rule 3 (+ rule 2)
2u - 10 // 10 is converted to unsigned int 10
// result after addition is unsigned int
// 4294967288 (-8 modulo 2^32 -> overflow)
0UL - 1LL // 0UL is converted to signed long long 0
// result after addition is signed long long -1
// NOTE: this example is different on
// cppreference and depends on the size of
// (unsigned) long which is 32-bits in my case
Files - text vs. binary mode
FILE *f = fopen("somefile.txt", "r+"); // text mode
FILE *b = fopen("somefile.txt", "r+b"); // binary mode
- Text mode converts
\r\nto\non input and the other way around on output on a Windows machine (and maybe other characters too) - because of this, fseek-ing into the middle of
\r\nhas some unexpected effects (probably undefined behavior)- reading might not produce the expected result and actually move the file pointer backwards before the
\r\nsequence
- reading might not produce the expected result and actually move the file pointer backwards before the
- this is one reason why fseek() should only be called with values of ftell() for text files (as per standard definition)
- reading from a text file or fseek-ing into it is slower than with a binary file
- counting line breaks is about 2-3x faster with a binary file (using fread(), a for loop and a 65K buffer)
- if the file is a text file fscanf, fgets, etc. work in both modes as expected (so if line endings do not matter, using binary mode can still be faster)
- Links
UTF8
- in both modes: watch out for UTF8 BOM
- first 3 bytes
- hex:
0xEF, 0xBB, 0xBF - uint:
239, 187, 191 - char:
-17, -69, -65 - Will probably not appear in a text editor and taken into account when calculating position (e.g. in Notepad++)
- Does appear in read chars in both text and binary mode and affects ftell()
- UTF8 characters (which may be more than 1 Byte) can be read in both modes. Generally it is best to just treat them as bytes/char* and pass them unmodified to printf/puts/etc. (which "just works"), if looking into single characters is not required.
- Note that strlen will not produce the "expected" results with multi-byte chars (i.e. count them as 2+)
- also the buffer holding them needs to account for this and potentially be bigger
- Links
Unity build
#includeall .c files in one file and only send that to the compiler- Comparing C/C++ unity build with regular build on a large codebase | Hereket
- Faster than non-incremental builds
- Slower than "clever" incremental builds with tools like cmake+ninja (only compiling changed files)
- Is also what raddbg uses (main .c file
#includesall .h and .c files - module .c files barely#includeanything on their own - not even the corresponding .h file) - Very simple compiler call, no need for cmake or a complicated build system: only need to specify one file, never change the compiler call
- Puts everything in one translation unit. This has advantages and disadvantages
- Mostly no need for header files and forward declarations anymore. Define functions before use and it just works.
- Using invasive APIs like windows.h is tricky, because they pollute your whole environment. Most often it is the "Rectangle" definition in windows.h (e.g. conflicting with raylib). Getting libraries like this to work might still involve creating separate translation units for all code that uses the library/API (in NetworkMonitor there is a separate translation unit for code using windows API or curl, which includes the windows API internally, since these conflicted with raylib).
- Using -DWIN32_LEAN_AND_MEAN can also help
- Sidenote: The C compiler is up to 10x faster than C++ compiler if templates and such are used in the C++ code
Macro best practices
- For multiple statements: wrap in do ... while(0) loop
- Rationale: This prevents incorrect usage in unbracketed if statements, which would most likely lead to unexpected results. Also statements require a semicolon at the end as delimiter.
#define foo(x) bar(x); baz(x)
if (x > 3)
foo(x)
// will lead to
if (x > 3)
bar(x);
baz(x);
#define foo_fix(x) do { bar(x); baz(x); } while(0)
- When a macro should not be defined in one case (e.g. debug builds), replace it with ((void)0) instead of leaving it blank
- Rationale: This will still work if the macro is used with the comma expression or ternary operator
#ifdef NDEBUG
#define debug_print(s) printf(s)
#else
#define debug_print(s) ((void)0)
#endif
for (int idx = 0; idx < len; ++idx, debug_print("foo")) { ... }
x > 0 ? debug_print("greater") : debug_print("smaller")
- For macros that return a value, which is not needed, consider explicitly discarding that value to avoid compiler warnings and misuse:
#define textf(f) ((void)snprintf(tempBuf, sizeof(tempBuf), f))
MSVC Build Insights
Finding build bottlenecks with C++ Build Insights - C++ Team Blog
Use the following to get insights into the build process of your C/C++ app. Find out which files are included way too often, which files take long to parse or compile.
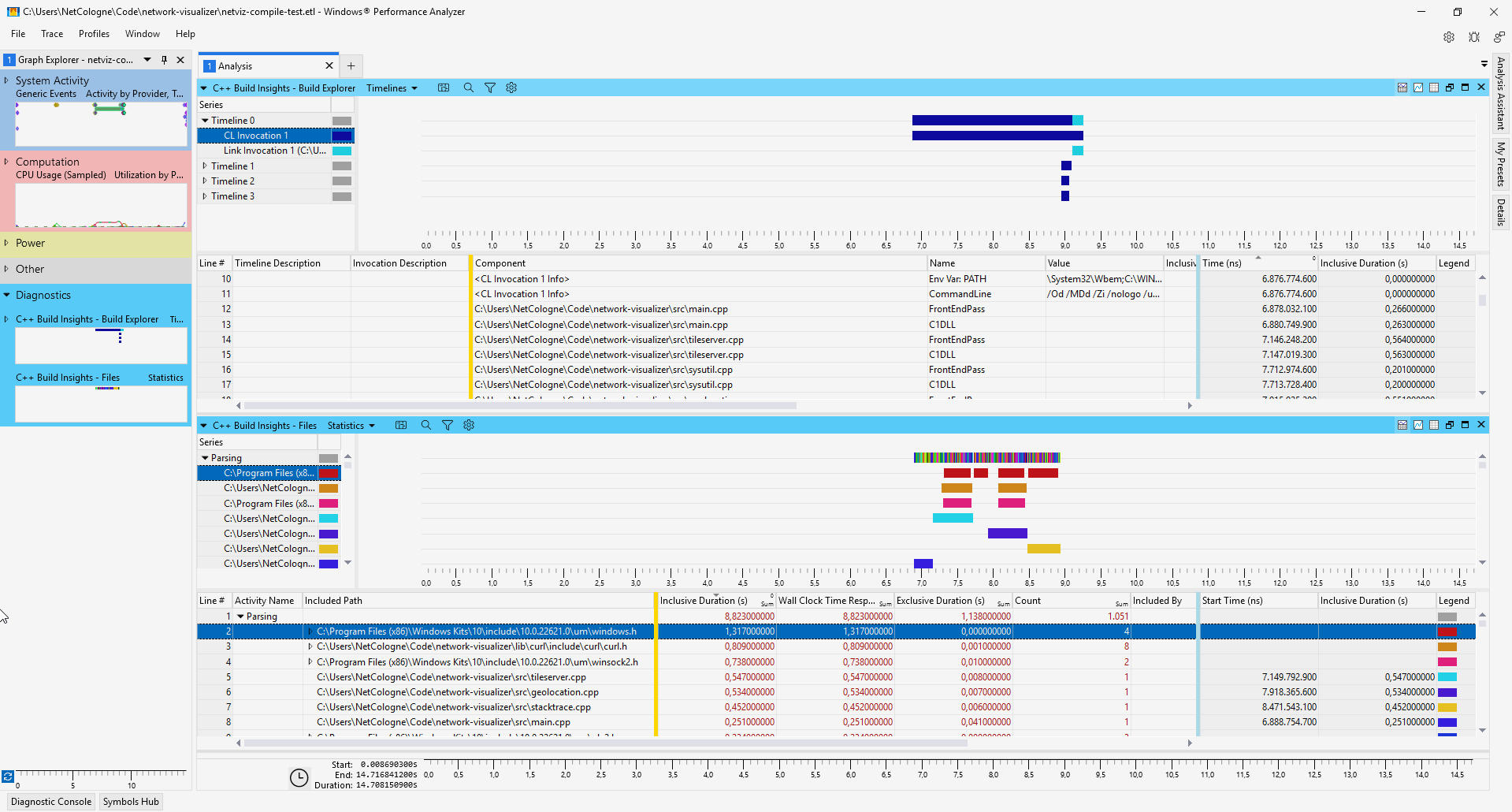
- Download and install the latest Visual Studio 2019. (vcperf seems to also be included in the Visual Studio Build Tools 2022)
- Obtain WPA by downloading and installing the latest Windows ADK.
- NOTE: I do not remember doing the following two steps, so maybe they can be skipped as of 05/2025
- Copy the perf_msvcbuildinsights.dll file from your Visual Studio 2019’s MSVC installation directory to your newly installed WPA directory. This file is the C++ Build Insights WPA add-in, which must be available to WPA for correctly displaying the C++ Build Insights events.
- MSVC’s installation directory is typically:
C:\Program Files (x86)\Microsoft Visual Studio\2019\{Edition}\VC\Tools\MSVC\{Version}\bin\Hostx64\x64. - WPA’s installation directory is typically:
C:\Program Files (x86)\Windows Kits\10\Windows Performance Toolkit.
- MSVC’s installation directory is typically:
- Open the perfcore.ini file in your WPA installation directory and add an entry for the perf_msvcbuildinsights.dll file. This tells WPA to load the C++ Build Insights add-in on startup.
- Open an elevated x64 Native Tools Command Prompt for VS 20XX.
- Obtain a trace of your build:
- Run the following command:
vcperf /start MySessionName. - Build your C++ project from anywhere, even from within Visual Studio (vcperf collects events system-wide).
- Run the following command:
vcperf /stop MySessionName outputFile.etl. This command will stop the trace, analyze all events, and save everything in the outputFile.etl trace file.
- Run the following command:
- Open the trace you just collected in WPA.
Clockwise Spiral Rule
How to read complex type declarations: https://c-faq.com/decl/spiral.anderson.html

Macro for optional function parameters
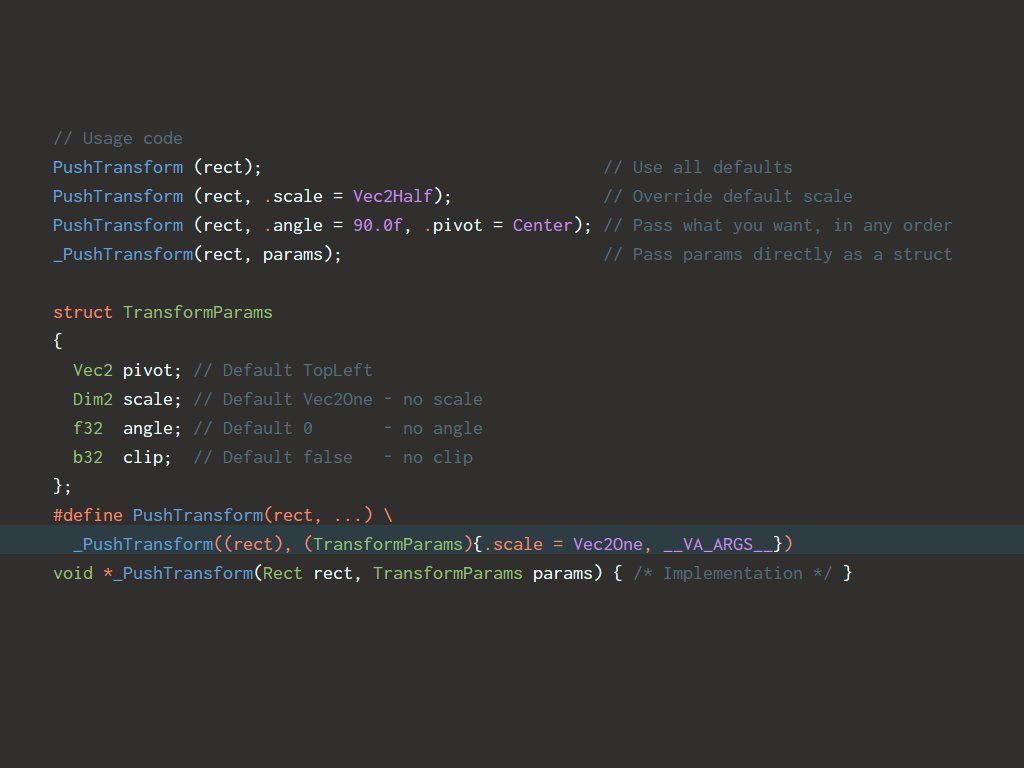
NOTE: Might not be ideal for hot paths. Function arguments are usually put in registers, structs are put in memory (so the assembly has to work with memory addresses and offsets, which is slower).
Platform Independent Code
The Basics of Platform API Design — Handmade Hero — Episode Guide — Handmade Hero
Don't do this:
int main(int argc, char **argv)
{
platformIndedependentCode1();
#ifdef _WIN32
doWindowsStuff();
#elif _LINUX
doLinuxStuff();
#endif
platformIndedependentCode2();
}
- Code will get very messy and unreadable fast (hard to follow the correct codepath for the current platform)
- Hard to maintain and extend. You need to search through all files to find all the ifdefs, if you want to add a platform
- Limits all platforms to the same control flow. Since only the smallest bits are abstracted, each platform has to follow the same basic structure.
Better approach:
- Have a platform specific main.cpp with the platform specific program entry (e.g. win32_main.cpp with WinMain, linux_main.cpp with main, etc.)
- Have that main function call a platform independent MainLoop() function, which starts up the actual (platform independent) program loop
- Inside the MainLoop() call out to platform specific functions from the platform layer (e.g. for reading files). These functions need to have the same API on all platforms and are defined in one common header file and implemented in the platform specific cpp file(s).
- You can chose to implement basic platform specific initialization (like creating a window) and loop code (like reading input or the message queue) directly in the platform specific main (i.e. wrapped around the MainLoop() call, passing messages and input in and getting video and sound data out) or abstract the code in functions and opaque structs, which are called/passed from MainLoop() (like you would reading a file). The example below uses the former approach.
- Selection of the desired platform code is done through passing the correct platform specific cpp file to the compiler (works well with #Unity build)
// program.h - main header file
void MainLoop();
void *loadFile(char *filepath);
// program.cpp
#include "program.h"
void MainLoop()
{
// main program flow
loadFile("foo.tmp");
}
// win32_main.cpp
#include "program.cpp"
int WinMain(...)
{
doWindowsInit();
while (!ProgramShouldClose)
{
// NOTE: Not in this example: passing of data between platform code and
// MainLoop() - possibly through some global state
handleMessages(); // platform specific
getInput(); // platform specific
MainLoop();
}
}
void *loadFile(char *filepath)
{
// do load and return
}
Weird Behavior calling into external library
When you get weird behavior around calling into an external library, make sure the header files and the lib/dll files linked against from that library match! (i.e. include exactly the header files used to compile the library files).
Otherwise the behavior is undefined and you will get crashes or weird stuff due to the stack being not handled correctly.
In my case a boolean function was returning -256 (which evaluates to true), instead of false or 0, but otherwise the code would run and behave normally. Replacing the header files with the correct version fixed this.